
관계 데이터 연산
- 관계 데이터 모델의 연산
- 원하는 데이터를 얻기 위해 릴레이션에 필요한 처리 요구를 하는 것이다.
- 관계 대수와 관계 해석이 있음
- 기능과 표현력 측면에서 능력이 동등하다.
- 관계 대수
- 원하는 결과를 얻기 위해서 데이터의 처리과정을 순서대로 기술
- 관계 해석
- 원하는 결과를 얻기 위해서 처리를 원하는 데이터가 무엇인지만 기술
- 관계 대수와 관계 해석의 역할
- 데이터 언어의 유용성을 검증하는 기준이다.
- 관계 대수나 관계 해석으로 기술할 수 있는 모든 질의를 표현 가능한 데이터 언어를 관계적으로 완전하다고 판단한다.
- 질의 : 데이터에 대한 처리 요구
관계 대수의 개념
- 원하는 결과를 얻기 위해서 릴레이션의 처리 과정을 순서대로 기술하는 절차 언어이다.
- 사용자가 원하는 데이터가 무엇인지, 검색 방법까지 기술
- 릴레이션을 처리하는 연산자들의 모임
- 대표 연산자 8개 (일반 집합 연산자 4개 + 순수 관계 연산자 4개)
- 폐쇄 특성이 존재한다
- 피연산자도 릴레이션, 연산의 결과도 릴레이션임
순수 관계 연산자
릴레이션의 구조와 특성을 이용하는 연산자
셀렉션 연산 σ
- 주어진 릴레이션에서 특정 조건을 만족하는 튜플을 구하는 연산자이다.
- σ조건식(릴레이션)
- Employee 릴레이션에서 직위가 ‘과장’인 튜플을 선택하는 연산
- σ직위='과장'(Employee)
프로젝션 연산 π
- 주어진 릴레이션에서 원하는 어트리뷰트만 뽑아내는 연산자이다.
- π속성 리스트(릴레이션)
- Employee 릴레이션에서 '직위' 어트리뷰트만 추출하는 연산
- π직위(Employee)
조인 연산 ⋈
- 두 개의 릴레이션에서 특정 조건을 만족하는 튜플을 결합해, 하나의 튜플로 만드는 연산
- 릴레이션1 ⋈조건식 릴레이션2
- Employee 릴레이션과 Department 릴레이션을 조인하는 연산
- Employee ⋈Employee.부서번호 = Department.부서번호 Department
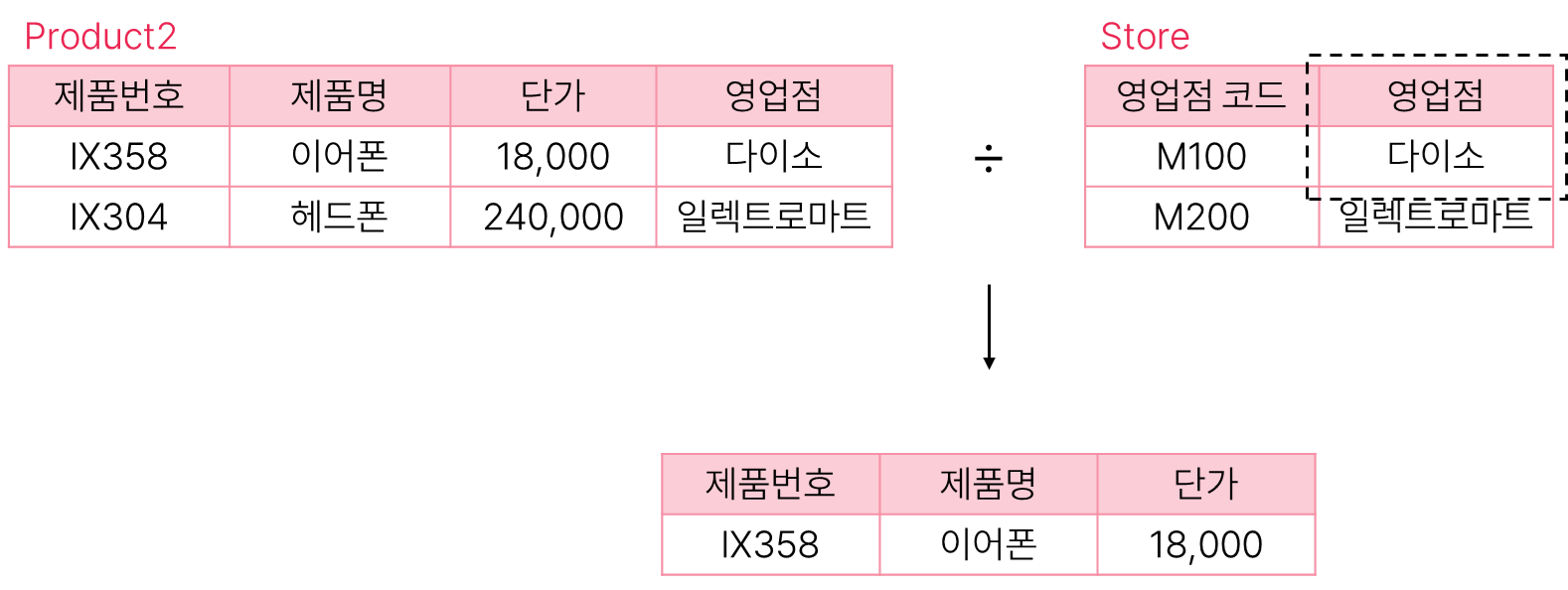
디비전(나누기) 연산 ÷
- 두 개의 릴레이션 R(X, Y)와 S(Y)에 대한 나누기 연산자이다.
- R(X, Y) ÷ S(Y)의 결과는 릴레이션 S의 모든 Y값과 관련된 릴레이션 R의 Y를 제외한 X값 출력하게 된다.
- 릴레이션1 ÷ 릴레이션2
- Product2 릴레이션을 Store 릴레이션으로 나누는 연산
- Product2 ÷ π영업점(σ영업점 코드='M100'(Store))
일반 집합 연산자
릴레이션이 튜플의 집합이라는 개념을 이용하는 연산자
합집합 연산 ∪
- 두 개의 릴레이션 중 어느 한쪽 또는 양쪽에 모두 존재하는 튜플을 구하는 연산자
- (π속성 리스트(릴레이션1)) ∪ (π속성 리스트(릴레이션2))
- Employee 릴레이션에서 직위가 ‘과장’인 튜플의 부서번호와 Department 릴레이션에서 사무실 위치가 ‘B201’인 튜플의 부서번호를 모두 구하는 연산
- (π부서번호(σ직위='과장'(Employee))) ∪ (π부서번호(σ사무실='B201'(Department)))
교집합 연산 ∩
- 두 개의 릴레이션에 모두 존재하는 튜플을 구하는 연산자
- (π속성 리스트(릴레이션1)) ∩ (π속성 리스트(릴레이션2))
- Employee 릴레이션에서 과장과 계장이 함께 근무하는 부서번호를 구하는 연산
- (π부서번호(σ직위='과장'(Employee))) ∩ (π부서번호(σ직위='계장'(Employee)))
차집합 연산 —
- 한 릴레이션에 속하지만, 다른 릴레이션에는 속하지 않는 튜플을 구하는 연산자
- (π속성 리스트(릴레이션1)) − (π속성 리스트(릴레이션2))
- 소속된 직원이 한 명도 없는 부서의 부서번호를 구하는 연산
- (π부서번호(Department)) − (π부서번호(Employee))
카티전 프로덕트 연산 X
- 두 개의 릴레이션에 존재하는 모든 튜플의 조합을 구하는 연산자
- 릴레이션1 X 릴레이션2
- Product 릴레이션과 Store 릴레이션에 대한 카티전 곱을 구하는 연산
- Product X Store